AI 视频生成的现状与工业化趋势
AI 视频生成是通过深度学习将文本、图像或音频转化为动态画面的技术。其核心已从早期的简单帧插值,演进为基于扩散模型(Diffusion Models)和 Transformer 架构的端到端生成,从而能够模拟物理规律相对真实的复杂场景。
到 2026 年 3 月,AI 视频已从“惊艳期”进入“工业化筛选期”。当前的竞争重点不再是生成 5 秒的电影感片段,而是精准的镜头控制、跨镜头的角色一致性,以及计算成本与产出质量的商业平衡。对于 2025 年底进入该领域的初学者,单纯依赖提示词(Prompt)难以产出商业级作品,必须建立一套完整的工作流,否则极易在昂贵的订阅费和算力消耗中迷失。
目前的市场梯队分布清晰:顶层是 Sora 2、Kling 2.6 和 Wan 2.6,具备强物理模拟能力且支持长视频生成;中层如 Hailuo、Seed Dance,主打特定风格或快速迭代;底层则是大量基于开源模型微调的垂直领域生成器。趋势显示,“生成”正在向“编辑”转移,纯文本生成视频(Text-to-Video)正被“图生视频(Image-to-Video)+ 视频生视频(Video-to-Video)”的复合流程取代。

核心技术原理解析:DiT 架构
掌握 AI 视频需理解 DiT(Diffusion Transformer)架构。它将视频视为时间维度上连续的图像块(Patches),在潜空间(Latent Space)中预测噪声,并利用 Transformer 处理时空关系,以维持物体在不同帧之间的稳定性。
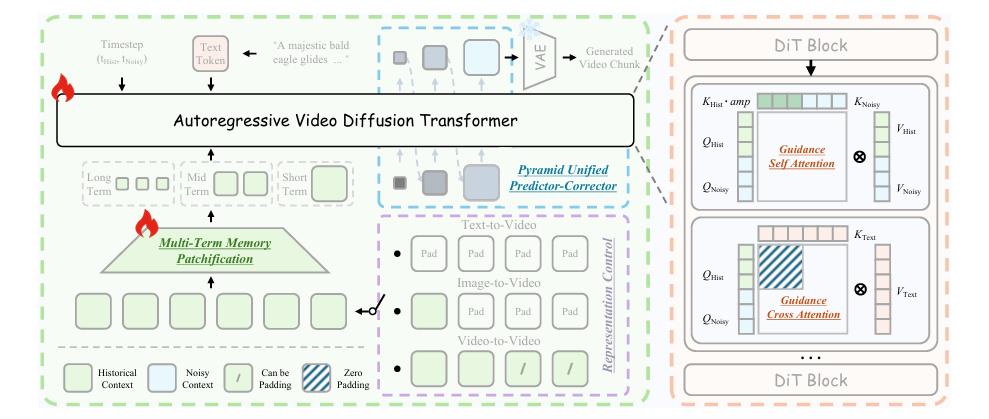
这也解释了为何“逻辑一致性”是最难攻克的痛点,例如人物行走时脚底与地面的融合问题,或液体流动违背重力方向的现象。
商业级 AI 视频分层生成工作流
建议采用“分层生成工作流”而非一次性生成全片,以确保视觉质量的可控性。
先使用 Midjourney v7 或 Stable Diffusion 3.5 生成高精度图像。设定统一的种子值(Seed)和角色参考图(Character Reference),产出故事开始、转折和结束的 3-5 张关键图。分辨率建议 16:9,并在提示词中明确光影描述(如:Cinematic Lighting, volumetric fog)。这能为视频模型提供视觉锚点,防止场景漂移。

将关键帧上传至 Kling 2.6 或 Sora 2。此时应重点描述“运动”而非“画面”,如“镜头缓慢向右平移,人物眼神微动”。将运动强度(Motion Slider)设在 3-5 之间(满分 10),过高会导致画面崩坏,过低则接近静态图。若面部变形,可尝试降低强度或使用局部重绘修正。
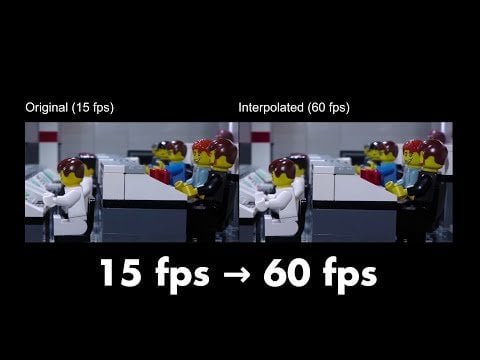
将片段导入剪辑软件,利用 Seed Edit 等工具处理衔接处。选取交接帧,通过 AI 补帧工具(Frame Interpolation)并选择“光流法(Optical Flow)”减少鬼影。若服装或背景出现细微偏差,可用视频掩码(Mask)锁定背景,仅允许人物运动,以消除跳帧感。
使用 ElevenLabs 生成配音,Suno v4 或 Udio 生成环境音。在剪辑软件中根据节奏点对齐音频,并利用 AI 口型同步工具处理对话。需确保音频采样率与视频帧率匹配,避免音画不同步。
主流 AI 视频工具对比分析
工具选择需权衡效果与成本,不同的模型在物理模拟和适用场景上存在明显差异。
| 模型名称 | 核心优势 | 成本等级 | 适用场景 |
|---|---|---|---|
| Sora 2 | 物理交互最强 | 极高 | 企业级广告 |
| Kling 2.6 | 人物动态/表情出色 | 中等 | 短剧、TikTok 宣传片 |
| Wan 2.6 | 支持私有化部署 | 较低 (开源) | B 端隐私数据需求 |
| Hailuo | 生成速度极快 | 较低 | 社交媒体快节奏出片 |
局限性与成本预警
AI 视频仍有明显局限,特别是在处理“精细物理碰撞”时表现糟糕,如纸张撕裂边缘常出现非自然形变。超长叙事的一致性也是痛点,视频超过 2 分钟后,角色易出现面貌变化。因此,对于医疗手术演示或精密工业组装等要求零误差的场景,不建议完全依赖 AI。